AI 换脸是通过深度学习算法提取目标人脸特征并将其替换至另一图像或视频中的技术。截至 2026 年 3 月,该技术已实现 4K 视频的实时处理且能同步肌肉微表情,其核心突破在于扩散模型(Diffusion Models)与 GAN 架构的融合,解决了以往像素叠加导致的违和感。
目前的工具链分化为两个阵营:便捷的云端一键式工具,以及高可控的本地开源生态。若需达到商业级视觉效果,单靠 App 难以实现,必须通过本地部署来精调参数。
底层逻辑:从关键点匹配到潜在空间映射
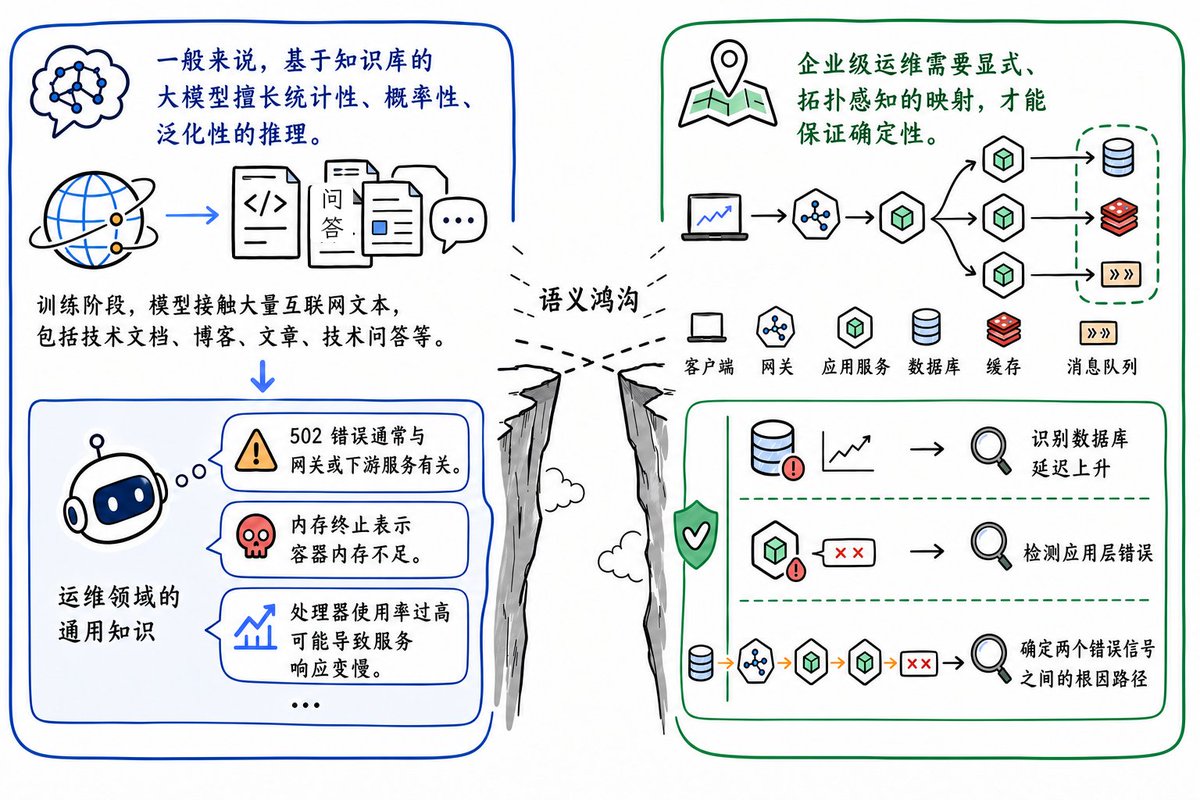
AI 换脸已从简单的像素覆盖进化为高维特征的重构。早期的换脸依赖关键点检测,通过定位眼、鼻、嘴等坐标将新脸像“贴纸”一样覆盖,导致侧脸或有遮挡时画面容易崩坏。而 Facefusion 或基于 Flux 架构的 Inpaint 流程采用了潜在空间映射(Latent Space Mapping)。
系统通过编码器(Encoder)将人脸转化为代表骨骼、纹理和光影的高维向量。AI 并非在搬运像素,而是在目标图像的潜在空间中替换特征向量。这意味着即便目标人物处于阴影中,AI 也能根据环境光线自动计算源人脸应有的阴影深浅,从而消除“贴纸感”。
Facefusion 本地部署实操指南
Facefusion 是目前开源社区更新最快、视频处理最稳定的工具,优于 roop 或 ReActor 插件。具体操作流程如下:
三类方案对比:Facefusion、ReActor 与 Flux LoRA
针对不同的应用场景,应选择不同的技术方案以平衡效率与质量。
| 方案 | 核心优势 | 主要局限 | 适用场景 |
|---|---|---|---|
| Facefusion | 视频处理快,内置增强 | 环境配置较为复杂 | 短视频、电影补拍 |
| ReActor (SD插件) | 集成SD生态,支持二次创作 | 视频渲染极慢且不稳定 | 电商模特、概念图 |
| Flux + LoRA | 光影极致真实,无接缝 | 训练门槛高,耗时久 | 高精商业广告 |
技术局限与失效场景
AI 换脸并非万能,在处理复杂动态环境时仍存在明显短板。主要失效场景包括:
- 极端光影:霓虹灯闪烁或强顶光会导致脸部瞬间“跳变”,产生视觉闪烁。
- 大幅度遮挡:当手掌或头发大面积覆盖面部时,AI 易在遮挡物下方生成多余皮肤,出现“双眼”或透视诡异现象。
- 极端情绪:剧烈愤怒或大笑时的肌肉形变常被 AI “平滑化”,导致结果虽然像本人,但失去情绪张力,呈现“僵尸脸”。
Q: 为什么我的换脸结果看起来像一张贴在脸上的面具?
这通常是因为源图与目标图的光影不一致,或 Face Enhancer 的 Blend 参数设置过高。建议降低增强权重,并尝试在 Facefusion 中调节 Color Transfer 算法以匹配肤色。
Q: 没有高性能 NVIDIA 显卡可以使用本地部署吗?
可以使用 CPU 运行,但渲染速度会慢 10-50 倍。对于视频处理,建议至少配备 8GB 显存的 GPU,否则在处理 4K 视频时极易出现 OOM(显存溢出)崩溃。
执行建议
初学者建议先尝试云端 Demo 或 API 工具,确认素材兼容性。若追求真实感,可按此路径进阶:配置 RTX 显卡 PC $\rightarrow$ 安装 Stable Diffusion 使用 ReActor 插件 $\rightarrow$ 尝试 Flux 重绘工作流。核心在于把控原图光影与微调增强参数,而非单纯依赖软件升级。